Prometheus 개념

프로메테우스는 쿠버네티스 모니터링 표준으로 사용되는 오픈소스 애플리케이션이다. 시스템이나 애플리케이션의 상태를 숫자 지표(metric)로 수집하고 저장하는 역할을 한다.
예를 들어 CPU 사용률, 웹 서버 요청 수, 에러율 같은 지표를 수집해 시간별로 저장하고, 이를 그래프나 알람으로 활용할 수 있다.
Prometheus 기본 구조

1. 쿠버네티스 노드(Kubernetes Node)
- 쿠버네티스 클러스터는 여러 개의 노드(Worker Node) 로 구성된다.
- 각 노드에는 Kubelet과 cAdvisor 같은 컴포넌트가 실행되어, 노드 및 파드의 리소스 사용량(CPU, 메모리, 네트워크, 디스크 등)을 실시간으로 수집한다.
- 이 정보들은 Prometheus Exporter 형태로 노출된다.
- kubelet이 /metrics 엔드포인트에서 메트릭 제공
- node-exporter가 OS 수준의 CPU, 메모리 사용량 제공
2. 프로메테우스(Prometheus)
- 프로메테우스는 각 노드나 파드의 Exporter로부터 데이터를 주기적으로 수집(scrape)한다.
- 수집된 데이터는 내부 시계열(time-series) 데이터베이스에 저장된다.
- 이 데이터베이스는 Persistent Volume(퍼시스턴트 볼륨) 에 연결되어 있다.
3. 퍼시스턴트 볼륨(Persistent Volume)
- 퍼시스턴트 볼륨은 프로메테우스 서버가 사용하는 스토리지 공간이다.
- 이곳에는 수집된 모든 메트릭 데이터(시계열 데이터)가 저장된다.
- 프로메테우스 Pod 하나가 이 퍼시스턴트 볼륨을 마운트하여 독점적으로 사용하게 된다.
4. 알럿 매니저(Alertmanager)
- Prometheus는 수집된 메트릭을 기반으로 알람 규칙(alert rule)을 평가한다.
- 특정 조건(CPU 90% 초과 등)이 만족되면 Alertmanager로 경고 메시지를 전달한다.
- Alertmanager는 그 알림을 Slack, Email, PagerDuty 등으로 전송한다.
5. 그래파나(Grafana)
- Grafana는 Prometheus의 API를 통해 데이터를 시각화한다.
- 사용자는 웹 대시보드에서 CPU 사용량, Pod 상태 등을 한눈에 볼 수 있다.
- Grafana는 Prometheus의 데이터를 읽기만 할 뿐, 자체적으로 데이터를 저장하지 않는다.
Prometheus & Grapana 설치
헬름 레포지토리에 prometheus-community 추가하고, 헬름 차트를 최신 상태로 동기화 한다.
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
다음과 같이 헬름 패키지를 다운로드 한다.
helm pull prometheus-community/kube-prometheus-stack
압축해제를 한다.
tar xvfz kube-prometheus-stack-54.0.1.tgz
디렉토리 이름에 버전을 포함시켜준다.
mv kube-prometheus-stack kube-prometheus-stack-54.0.1
디렉토리 안에 들어가서 values.yaml 파일을 확인한다.
cd kube-prometheus-stack-54.0.1
ls
Prometheus & Grapana 설정 변경
프로메테우스 기본 설정에서 변경할 값들은 다음과 같다.
설정을 수정하기 위해 복사본을 만든다.
cp values.yaml my-values.yaml
service.type: ClusterIP → NodePort
- Prometheus 웹 콘솔(기본 포트 9090)은 원래 쿠버네티스 클러스터 내부에서만 접근 가능하다.
- 하지만 실습 환경처럼 외부(브라우저나 로컬 PC)에서 접속하려면
- NodePort 타입으로 바꿔야 외부 IP를 통해 접근할 수 있다.
→ http://<노드IP>:<노드포트> 형태로 접속 가능
→ 외부 사용자가 직접 메트릭, 타임시리즈, Alert 상태를 볼 수 있다.
serviceMonitorSelectorNilUsesHelmValues: true → false
- 해당 옵션은 Prometheus가 어떤 ServiceMonitor를 감시할지를 결정한다.
- true: Helm 차트 내부에 정의된 기본 ServiceMonitor만 수집한다.
- false: 클러스터 전체에 존재하는 모든 ServiceMonitor를 자동 인식한다.
- 즉, 여러 네임스페이스에 존재하는 exporter (예: Node Exporter, kube-state-metrics 등)도 Prometheus가 자동으로 감시하려면 반드시 false로 바꿔야 한다.
→ Prometheus가 쿠버네티스 전역 리소스를 모니터링 가능.
→ Helm 설치 시 자동 배포된 exporter들이 정상적으로 수집됨.
retention: 10d
- Prometheus의 시계열 데이터는 기본적으로 짧은 기간(약 15일 미만)만 보존된다.
- retention을 통해 데이터를 얼마나 오래 저장할지를 지정한다.
- 여기서 10d는 “10일간 데이터 보존”이라는 뜻이다.
→ 오래된 메트릭 자동 삭제
→ PV 공간 관리 가능
→ 운영 환경에서는 보통 15~30일로 설정한다.
retentionSize: "1GiB"
- Prometheus는 시계열 데이터를 블록 형태로 저장하기 때문에
- 데이터가 무한히 쌓이면 PV 용량을 초과한다.
- 이를 방지하기 위해 보존 용량을 제한한다.
→ Prometheus 데이터가 1GiB를 넘기면 오래된 블록부터 자동 삭제된다.
→ 불필요한 로그 폭증 방지.
storageSpec
- 기본값: 비어 있음 ({})
- 기본값으로 두면 Pod가 재시작될 때마다 데이터가 모두 사라진다.
- Prometheus의 TSDB(시계열 데이터베이스)는 /prometheus 경로에 저장되는데, 이걸 퍼시스턴트 볼륨(PV) 에 연결해야 데이터가 유지된다.
- 예시 설정
- storageSpec: volumeClaimTemplate: spec: accessModes: ["ReadWriteOnce"] resources: requests: storage: 10Gi
→ Prometheus Pod가 재시작되어도 메트릭 데이터 유지
→ PV에 실제 파일(wal, chunks, data 등) 저장
→ 운영 환경에서 필수 설정이다.
resources.requests.storage: 50Gi (혹은 다른 크기)
- PV 크기를 정의하는 부분이다.
- Prometheus는 시계열 데이터를 대량으로 저장하므로 여유 공간을 확보해야 한다.
→ 10Gi~50Gi 정도 설정 시 중장기 보존 가능
→ 작은 용량(예: 1Gi)은 실습용, 운영에는 비추천.
이어서 그라파나도 설정도 수정해줘한다.
cd kube-prometheus-stack-54.0.1/charts/grafana
vi values.yaml
다음과 같은 항목들을 수정해준다.
service.type: ClusterIP → NodePort
- Grafana 웹 UI(기본 포트 3000)는 내부 전용이므로 외부 접속이 불가능하다.
- Prometheus와 마찬가지로 NodePort로 변경해야
- 브라우저에서 바로 대시보드를 볼 수 있다.
→ http://<노드IP>:<NodePort> 형태로 접근 가능
→ Grafana 로그인 창 접속 가능
→ 내부용 ClusterIP가 외부 접속용으로 변경됨.
persistence.enabled: false → true
- Grafana의 대시보드, 설정, 사용자 계정 정보는 Pod 내부의 /var/lib/grafana 에 저장된다.
- Pod가 재시작되면 이 디렉토리 내용이 모두 초기화된다.
- 따라서 PVC를 연결해 데이터를 영구 보존해야 한다.
→ 재시작 후에도 기존 대시보드 유지
→ 커스텀 설정, 로그인 계정 등 영구 저장 가능.
storageClassName: default
persistence.enabled를 켜면, 어느 스토리지 클래스로 PVC를 생성할지 지정해야 한다.
보통 쿠버네티스 클러스터 기본 스토리지 클래스(default)를 사용한다.
AWS면 EBS, GCP면 PD, 로컬이면 hostPath 등 환경에 맞게 자동 연결된다.
→ Grafana의 PV가 정상적으로 생성됨
→ 퍼시스턴트 스토리지에 설정 및 데이터 저장.
size: 10Gi
- Grafana가 사용하는 PV의 용량이다.
- 보통 대시보드 정보나 사용자 계정 데이터는 크지 않으므로 5~10Gi로 충분하다.
→ 10Gi PV 생성
→ 재시작 시에도 모든 대시보드 및 설정 유지.
Prometheus 생성
먼저, 프로메테우스를 설치를 위한 네임스페이스를 생성한다.
kubectl create namespace mymonitoring
네임스페이스가 생성되었는지 확인한다.
kubectl get namespace
위와 같이 정상적으로 생성된 것을 확인할 수 있다.
헬름으로 해당 네임스페이스에 프로메테우스를 설치해준다.
helm install --namespace mymonitoring --generate-name prometheus-community/kube-prometheus-stack -f my-values.yaml
설치가 완료되면 STATUS가 deploy인 것을 확인할 수 있다.

프로메테우스가 성공적으로 설치되었는지 확인한다.
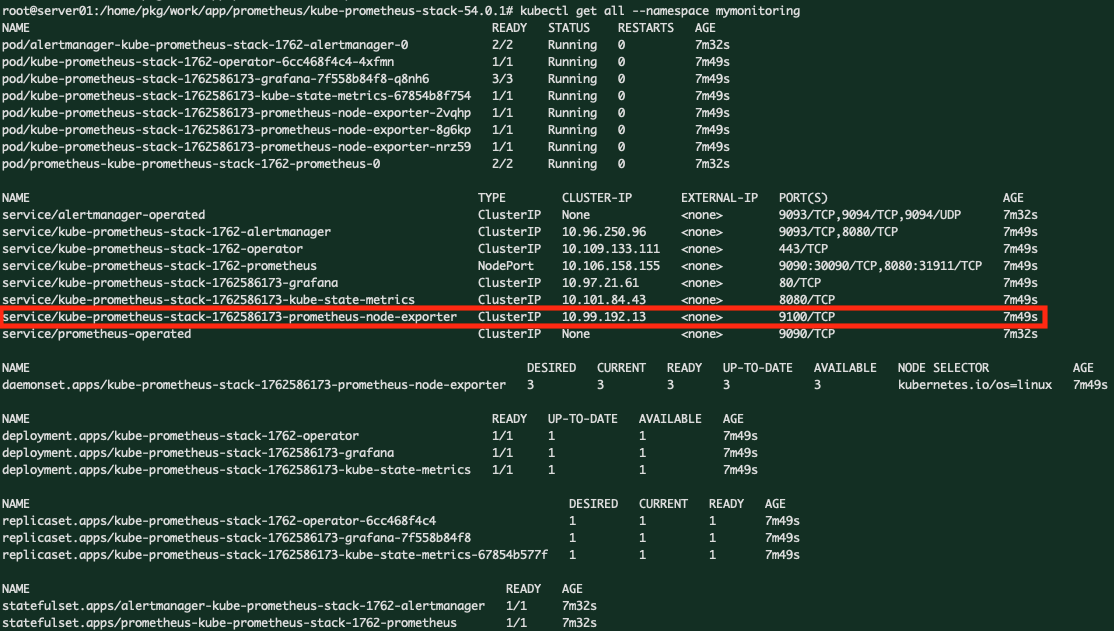
kubectl get all --namespace mymonitoring
또한 여러 파드들이 올라와 있는 것을 확인할 수 있는데, 각 파드들의 역할은 다음과 같다.
| 컴포넌트 | 파드 위치 | 역할 설명 |
| Prometheus | server03 | 모든 노드(node-exporter, kube-state-metrics 등)에서 메트릭을 수집하고 자체 시계열 DB에 저장함. NodePort(30090)로 외부에서 접근 가능. |
| Grafana | server03 | Prometheus에서 수집한 데이터를 시각화. 웹 대시보드 형태로 표현. |
| Alertmanager | server02 | Prometheus의 경고 룰(Alert Rule)에 따라 Slack 등으로 알림 발송. |
| kube-state-metrics | server03 | 쿠버네티스 오브젝트 상태(Deployment, Pod, Node 등)를 Prometheus 형식으로 변환해 제공. |
| node-exporter | server01, server02, server03 | 각 노드의 하드웨어/OS 메트릭을 수집하는 agent. CPU, 메모리, 파일시스템, 네트워크 등 노드 단위 메트릭을 제공. DaemonSet 형태로 모든 노드에 배포됨. |
프로메테우스를 통한 데이터 확인
프로메테우스에서 매트릭 정보를 가져오는 서비스는 node-exporter다.
node-exporter를 웹 브라우저에서 확인할 수 있도록 포트포워딩을 설정해준다.
로컬 호스트의 8080포트를 9100포트로 포트포워딩 해준다.

웹 브라우저에서 127.0.0.1:8080으로 접속하면 다음과 같이 프로메테우스 node-exporter를 확인할 수 있다.

이번에는 프로메테우스에 직접 접속해본다. service/kube-prometheus-stack-1762-prometheus 서비스를 통해 프로메테우스에 직접 접속할 수 있다. 해당 프로메테우스 파드는 server03에 떠있는 것을 확인할 수 있다.

로컬 호스트의 30090포트를 server03의 30090포트로 포트포워딩 해준다.
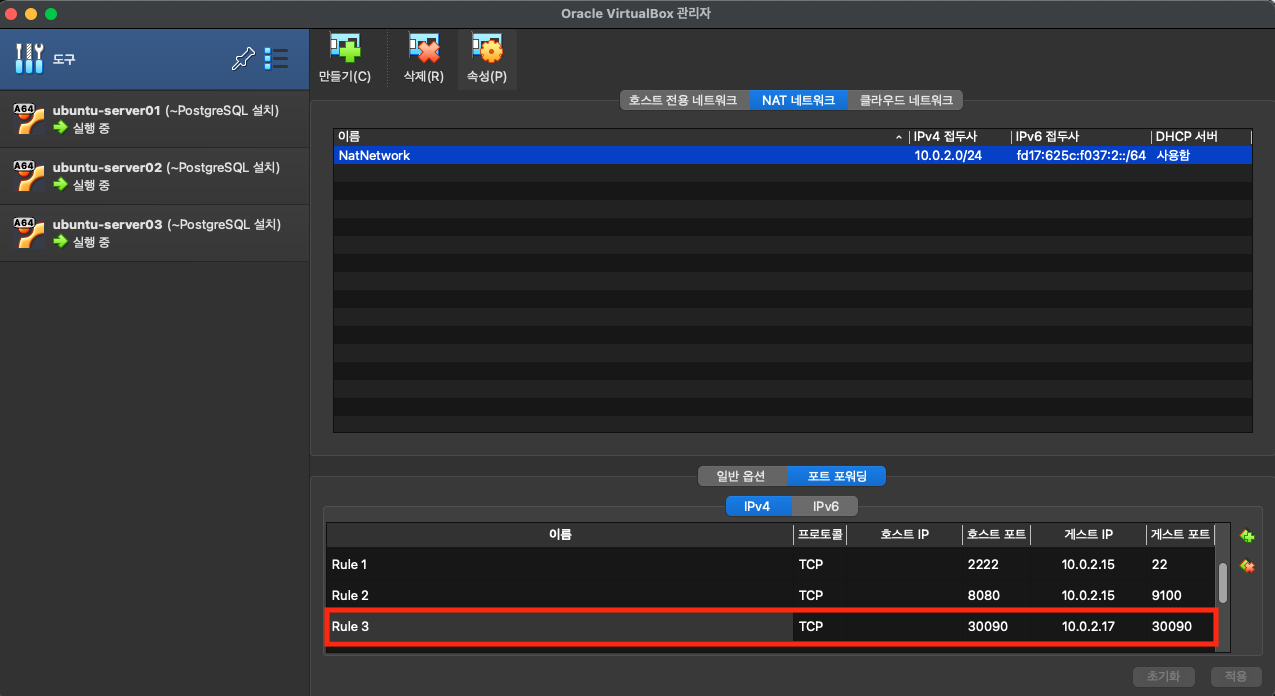
웹 브라우저에서 127.0.0.1:30090으로 접속하면 다음과 같이 프로메테우스 화면을 볼 수 있다.

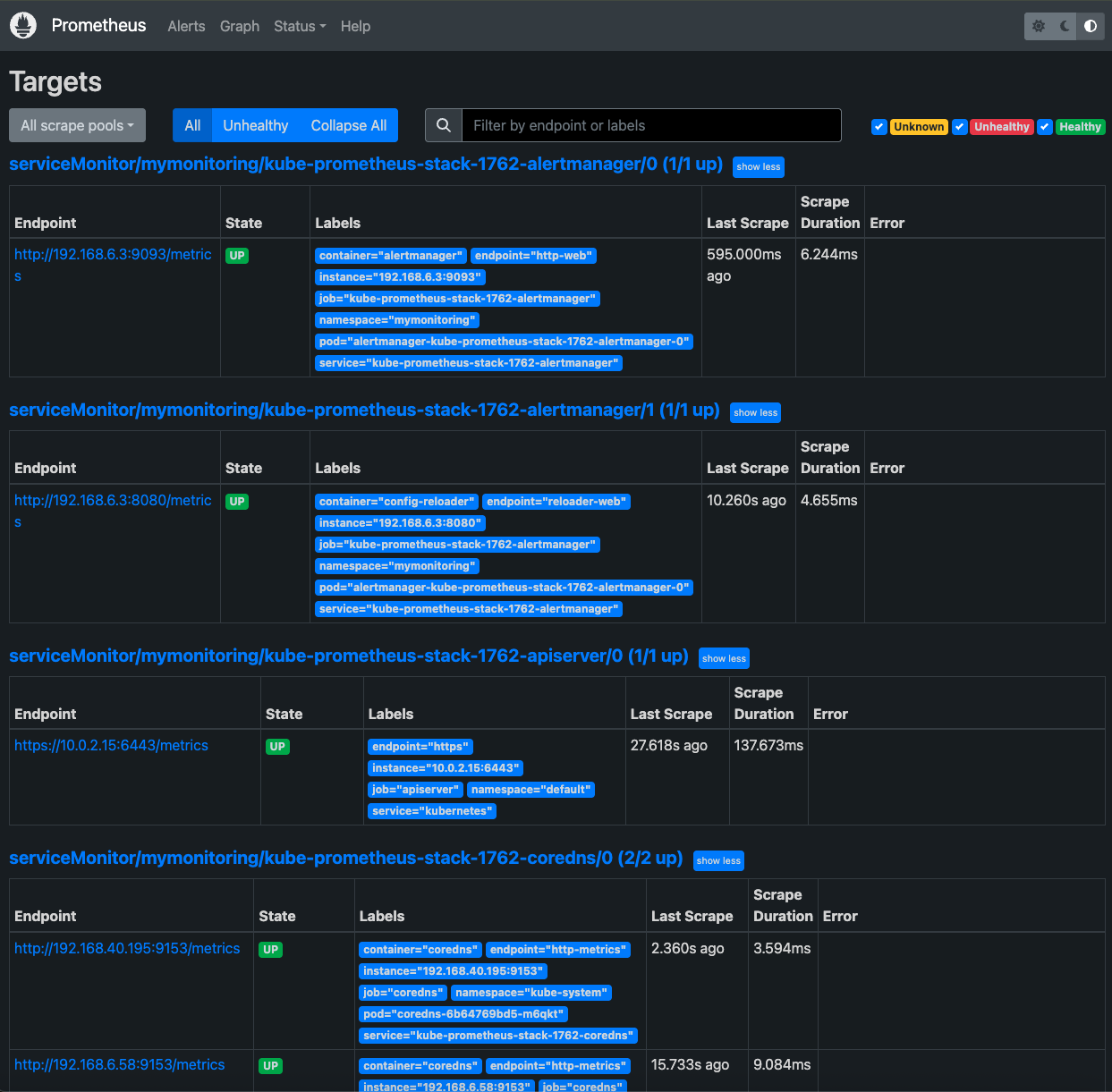
위와 같이 프로메테우스 UI에서 다양한 정보를 검색할 수 있다.
Reference
- https://kubernetes.io/ko/docs/home/
- 정철원, ⌜한권으로 배우는 도커&쿠버네티스⌟, 한빛미디어(주), 2024, 556쪽