AWS에서는 클라우드 환경의 복잡성 때문에 전통적인 온프레미스 환경과는 다른 접근 방식의 모니터링이 필요하다. AWS 리소스는 동적으로 생성되고 삭제되며, 다양한 서비스들이 서로 연결되어 있어 통합적인 모니터링 전략이 중요하다.
모니터링
AWS의 모니터링 생태계는 다음과 같이 이루어져있다.
모니터링/알림 서비스
- CloudWatch Alarm: 지표 기반의 알림 시스템
- Amazon SNS: 알림 전달 서비스
가동 상태 검사(대시보드)
- AWS CloudWatch 대시보드: AWS 리소스와 애플리케이션의 모니터링 데이터를 시각적으로 표현한 대시보드
모니터링 대상
- CloudWatch Logs: 로그 데이터 저장
- CloudWatch Metrics: 수치 데이터 저장
또한 각 AWS 리소스나 애플리케이션 뿐만 아니라 AWS가 관리하는 인프라도 장애가 발생할 수도 있는데, 이러한 내용들은 다음과 같이 AWS Health에서 확인할 수 있다.

Amazon CloudWatch Metrics
CloudWatch Metrics는 AWS의 핵심 모니터링 서비스다. 모든 AWS 서비스가 자동으로 기본 지표들을 CloudWatch로 전송하며, 사용자는 이를 통해 리소스의 상태와 성능을 실시간으로 파악할 수 있다.
AWS CloudWatch Metrics는 다음과 같은 특징이 존재한다.
- 자동 지표 수집: EC2, RDS, Lambda 등 대부분의 AWS 서비스에서 자동으로 지표 전송
- 사용자 정의 지표: 애플리케이션별 맞춤 지표 생성 가능
- 시계열 데이터베이스: 시간에 따른 데이터 변화 추적
- 다양한 통계 기능: 평균, 최대, 최소, 합계 등의 집계 연산
CloudWatch Metrics Insight
이는 CloudWatch의 고급 쿼리 기능으로, SQL과 유사한 문법을 사용해 복잡한 지표 분석이 가능하다. 예를 들어, 다음과 같은 분석이 가능하다.
- 여러 인스턴스의 평균 CPU 사용률 계산
- 특정 시간대의 네트워크 트래픽 패턴 분석
- 리소스별 성능 비교 분석
cf. 동일한 리소스에 서로 다른 지표를 표시하거나 서로 다른 리소스의 동일한 지표를 표시하여 리소스 가동 상태를 파악할 수 있다.
통합 CloudWatch 에이전트
통합 CloudWatch 에이전트를 EC2에 설치하여 EC2에서 기본적으로 수집하는 지표 뿐만 메모리, 디스크 사용률 등 OS 계층에서 수집하는 지표도 수집 가능하다.
Amazon CloudWatch Alarm
CloudWatch Alarm은 지표 기반의 자동화된 알림 시스템이다. 단순히 알림을 보내는 것을 넘어서, 경보 상태가 변경되었을 때 실행할 작업도 정의할 수 있다.
경보 종류는 다음과 같다.
- 정적 임계값 기반: 사용자가 설정한 고정된 기준값
- 이상 탐지 기반: 과거 지표 분석을 기반으로 동적 임계값 설정
- 수식 기반: 여러 지표를 조합한 복합 조건
- 복합 경보: 다른 여러 경보 상태를 종합한 경보
경보 상태는 다음과 같다.
- OK: 정상 상태 (임계 값 범위 내)
- ALARM: 경보 발생 상태 (임계 값 범위 밖)
- INSUFFICIENT_DATA: 데이터 부족으로 경보 상태를 판단할 수 없는 상태.(경보 운영 시작 직후, 지표 누락 등)
경보 평가 기간
CloudWatch는 Alarm은 경보상태를 적절히 변경할 수 있도록 지표를 평가하는 기간과 타이밍을 설정할 수 있다.
CloudWatch Alarm이 경보 상태를 평가하는 요소는 다음과 같다.
1. 기간 (Period)
- 경보의 임계값 범위를 벗어나지 않거나 범위 안에 있는 간격으로, 평가한 시점을 데이터 포인트라고 한다.
- ex. 5분 간격으로 데이터를 수집한다면, 각 5분마다 하나의 데이터 포인트가 생성된다
2. 평가 기간 (Evaluation Period)
- 경보 평가 대상이 되는 가장 최근의 데이터 포인트 개수를 의미한다.
- ex. 평가 기간이 3이라면, 최근 3개의 데이터 포인트를 검토하게 된다.
3. 경보에 대한 데이터 포인트 (Datapoints to Alarm)
- 평가 기간 중에서 경보 상태를 결정하는 데 필요한 데이터 포인트 개수를 의미한다
- ex. 3개 중 2개가 임계값을 초과하면 경보 발생
위 내용들을 활용하여 테스트 시나리오를 짜보면 다음과 같다.
- 데이터 포인트 기간: 5분
- 평가 기간: 3개 데이터 포인트 (15분간)
- 경보 조건: 3개 중 2개가 임계값 초과
- 지표: CPU 사용률
위 설정에서 CPU 사용률을 90% 이상으로 지정하고, 기간을 5분으로 설정한다면 이 경보는 5분 간격으로 데이터를 수집한다. 지난 3회 중에서 2회가 90% 이상이면 ALARM 상태로 변하게 되는 것이다.
그러면 왜 이렇게 복잡한 설정이 필요한 것일까? 이유는 다음과 같다.
1. 오탐 방지
- 일시적인 CPU 스파이크로 인한 불필요한 알림 방지
- 진짜 문제 상황과 일시적 현상 구분
2. 안정성 확보
- 네트워크 지연이나 일시적 장애로 인한 데이터 누락 대응
- 더 안정적이고 신뢰할 수 있는 알림 시스템 구축
3. 유연성 제공
- 서비스 특성에 맞는 맞춤형 알림 정책 설정
- 중요도에 따른 다양한 민감도 조절
경보 작업 (Alarm Actions)
경보 상태가 변경되었을 때 동작을 설정할 수 있는 기능이다. 경보 작업을 통해 운영자에게 알림을 보내는 것이 일반적이다.
1. OK → ALARM
- 정상에서 문제 상황으로 전환을 의미.
- 즉각적인 알림 실행.
2. ALARM → OK
- 문제 해결 완료 알림을 의미.
- 복구 확인 메시지 전송.
3. INSUFFICIENT_DATA
- 데이터가 부족하여 판단할 수 없는 상황을 의미.
- 모니터링 시스템 자체의 문제일 수 있음을 알림.
이러한 알림들을 보낼 때 활용할 수 있는 서비스가 Amazon SNS이다.
Amazon SNS

Amazon SNS (Simple Notification Service)는 발행/구독(Publish/Subscribe) 모델 기반의 메시지 송수신 서비스다.
즉, 특정 이벤트가 발생했을 때, 그 사실을 여러 구독자에게 자동으로 알려주는 중개 시스템이다.
- Publisher (발행자): 메시지를 SNS 주제(Topic)에 발행하는 쪽
→ 예: CloudWatch Alarm, AWS Lambda, EC2, 사용자 애플리케이션 - Subscriber (구독자): SNS 주제로부터 메시지를 받는 쪽
→ 예: Email, SMS, AWS Lambda, Amazon SQS, Amazon Kinesis
SNS는 AWS 내부 서비스뿐만 아니라 외부 이메일/SMS로도 알림을 보낼 수 있다.
예를 들어, 서버의 CPU 사용률이 90%를 넘었을 때 CloudWatch Alarm → SNS → 이메일 발송이 자동화된다.
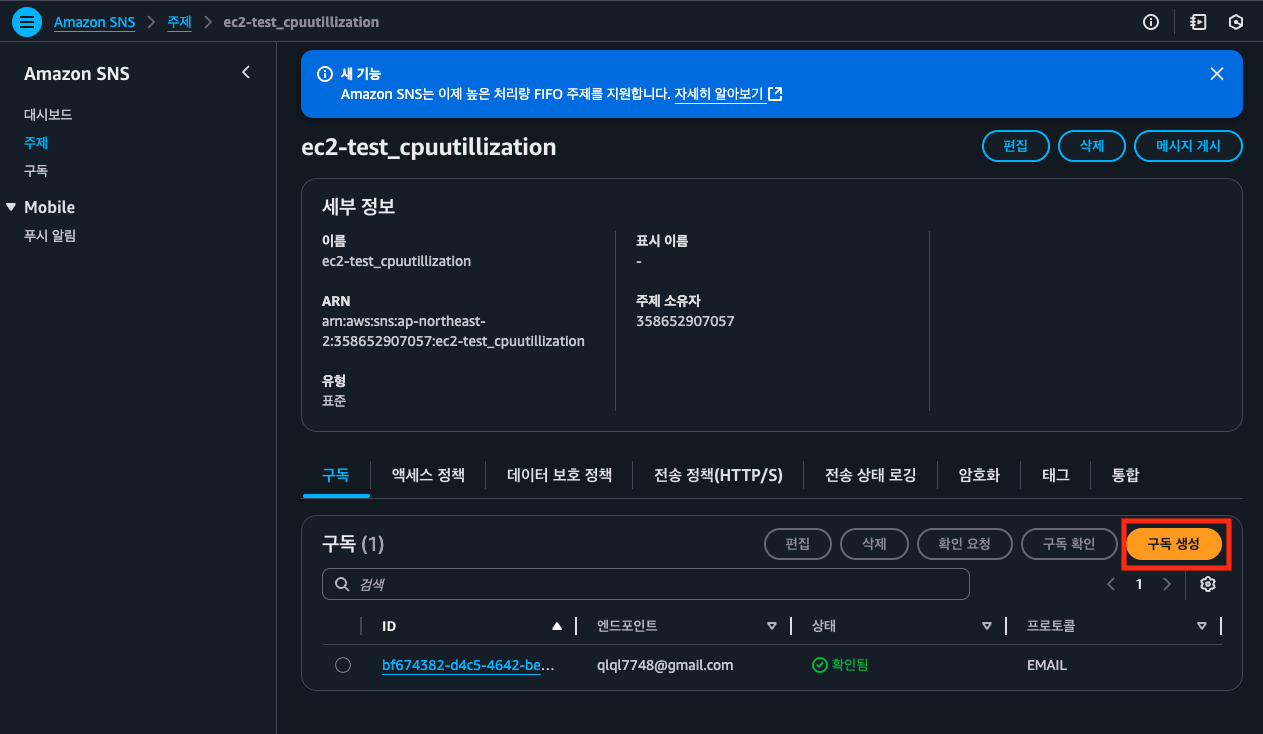
Amazon SNS를 이용한 CloudWatch Alarm 알림 설정하기
Amazon SNS를 이용하여 CloudWatch Alarm 알림 설정을 다음과 같이 해보자. EC2 인스턴스 한대의 CPU 사용률이 90% 이상 되었을 때 알리는 경보를 생성한다.
다음과 같이 CPUUtillizations를 선택하고 [지표 선택]을 클릭한다.

또한 다음과 같이 설정해준다.

지표 선택 (Metrics)
- CloudWatch 콘솔에서
“경보 생성(Create alarm)” → “지표 선택(Select metric)” 클릭 - 예시: EC2 → Per-Instance Metrics → CPUUtilization 선택
이 지표는 EC2의 CPU 사용률을 나타낸다.
그래프가 표시되며, 추후 임계값 기준으로 경보를 만든다.
기간 설정 (Period)
- 데이터 수집 주기(Period) 를 지정한다.
- 최소 1분 (AWS가 기본적으로 1분 단위로 메트릭을 수집함)
- 선택한 기간 동안의 평균/최대/최소값 중 무엇을 기준으로 할지 선택 가능
- 예: “평균(Average)” 또는 “최대(Maximum)”
조건 설정 (Threshold)
- 경보 조건을 지정한다.
- 예: CPU 사용률 ≥ 90%
- 평가 데이터 포인트(Evaluation points) 도 설정한다.
- 예: “3/5” → 5개의 최근 측정 중 3회 이상이 조건을 만족하면 경보 발생
다음과 같이 ALARM 상태, OK 상태 모두 알림 전송 대상으로 같은 SNS 주제를 지정해준다.

알림 대상 설정 (Notifications)
- [알림 추가(Add notification)] 클릭 → SNS 주제(Topic) 선택
- 기존 주제를 선택하거나 새로 생성 가능
- 새 주제 생성 시:
- 주제 이름: ex2-test_cpuutillization
- 구독자 이메일 주소 입력
- 알림 받을 상태 선택:
- ALARM (조건 충족 시)
- OK (정상 복귀 시)
- INSUFFICIENT_DATA (데이터 부족 시)
다음과 같이 설정 후 [다음] 버튼을 클릭한다.

다음과 같이 여태 설정한 내용들을 확인하고, [경보 생성] 버튼을 클릭해서 생성해준다.

SNS은 구독자의 승인 없이는 메시지 전송이 되지 않기 때문에 경보 생성 시 최초 1회, 입력한 이메일 주소로 확인 메일이 간다.

위의 [Confirm subscription] 버튼을 클릭하면 아래와 같이 승인된다.

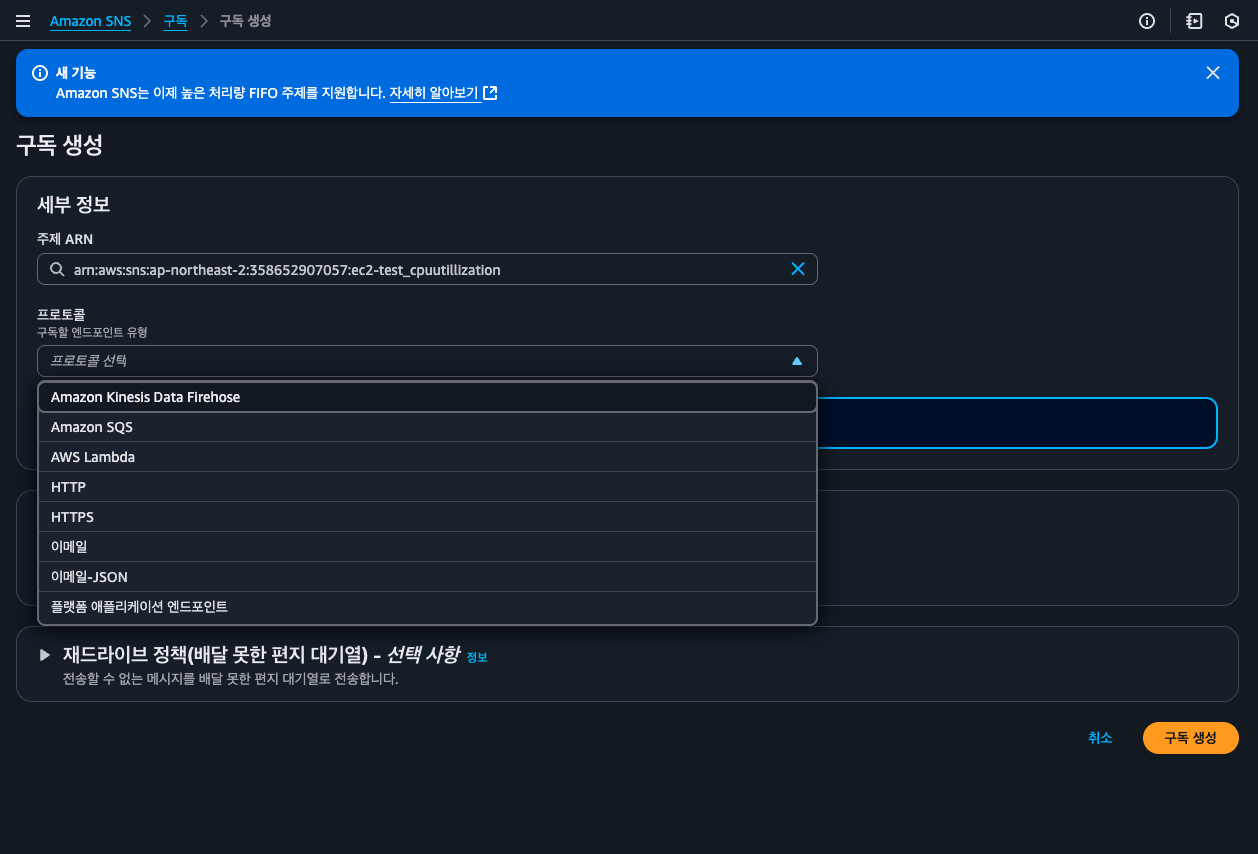
추가로, 이메일 이외에도 다양한 구독 방식을 선택 가능하다. 써드 파티 서비스들과 연동시 참고한다.